赛优市场店员积累了丰富的神秘顾客经验,严谨,务实,公平,客观.真实的数据支持!

基于大模子的Agent青岛酒店神秘顾客,照旧成为了大型的博弈游戏的高档玩家,况兼玩的如故德州扑克、21点这种非完整信息博弈。
来自浙江大学、中科院软件所等机构的商讨东谈主员建议了新的Agent进化战略,从而打造了一款会玩德州扑克的“奸巧”智能体Agent-Pro。
通过束缚优化自我构建的天下模子和步履战略,Agent-Pro掌持了虚张声威、主动毁灭等东谈主类高阶游戏战略。

Agent-Pro以大模子为基座,通过自我优化的Prompt来建模游戏天下模子和步履战略。
比较传统的Agent框架,Agent-Pro粗略变通地交代复杂的动态的环境,而不是仅专注于特定任务。
况兼,Agent-Pro还不错通过与环境互动来优化我方的步履,从而更好地斥逐东谈主类设定的认识。
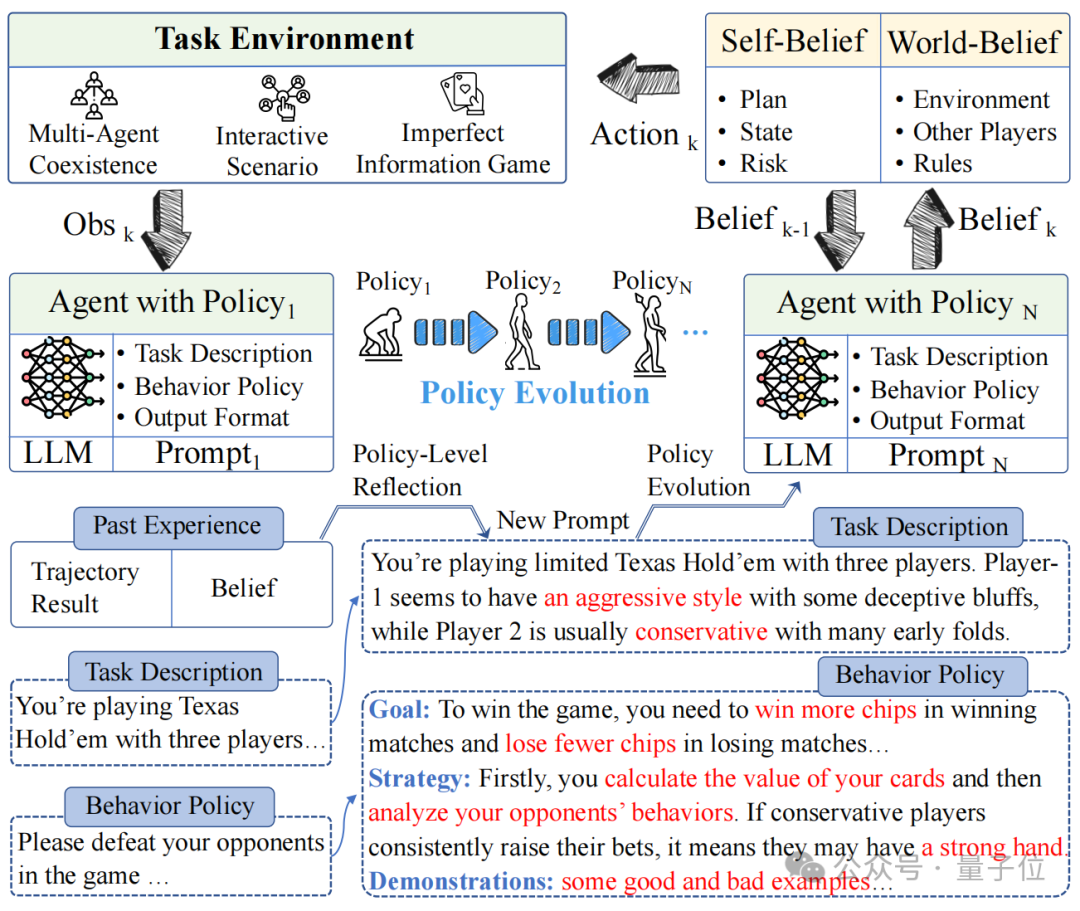
同期作家还指出,在竞争、公司谈判和安全等履行天下中遭受的情景,大多不错概括为multi-agent博弈任务,而Agent-Pro通过对这类情境的商讨,为处分浩大履行天下的问题提供了有用战略。
那么,Agent-Pro在博弈游戏中的发挥究竟如何呢?
进化出游戏天下模子
在商讨中,作家使用了“21点”和“有限注德州扑克”这两款游戏对Agent进行了评估。
领先简要先容下两个博弈游戏的基本轨则。
21点
游戏中包含一个庄家和至少又名玩家。
玩家不错看到我方的两张手牌, 以及庄家的一张明牌,庄家还挫折了一张暗牌。玩家需要决定是连接要牌(Hit)如故停牌(Stand)。
游戏的认识是在总点数不跳跃21点的前提下,尽量使总点数跳跃庄家。
有限注德州扑克
游戏开动阶段为Preflop阶段,每位玩家将得回两张只属于我方且对其他玩家遮蔽的私牌(Hand)。
这一意外决定引起了广泛的关注和讨论。作为中国快餐行业的领军品牌,老乡鸡以其标准化流程、全产业链管理和独特的出圈方式而闻名。然而,此次撤回上市的决策使人们对老乡鸡背后的考虑和战略调整产生了浓厚的兴趣。在快餐品牌陆续尝试登陆资本市场却屡屡遇挫的背景下,老乡鸡的撤回举措引发了对于快餐行业未来发展趋势的思考,许多人不解明明在疫情期间依旧保持着较好发展势头的老乡鸡为何会突然停止IPO计划,据悉在今年3月老乡鸡就已成为上交所受理的唯一一家中式快餐企业,此番IPO门前的急刹车,也是因为综合多方面考虑,助力市场更加快速恢复经济活力,主动为科技类企业让路。然而,选择主动放弃在A股上市,则面对内外的压力和竞争,如何找到突破口并保持竞争力,成为了摆在老乡鸡面前的重要课题。

随后,会有五张全球牌面(Public Cards)轮番发出:领先翻牌(Flop)3 张,其次转牌(Turn)1张,临了是河牌(River)1张。
玩家有四种选拔:弃牌(fold)、过牌(check)、跟注(call)或加注(raise)。
认识是诳骗我方的两张Hand和五张Public Cards随性组合,尽可能构造出最好的五张扑克牌组合。
在“21点”当中,通常是使用GPT-4作为基础模子,Agent-Pro的发挥跳跃了ReAct框架。
在手牌换取的情况下,二者的发挥如下图所示。
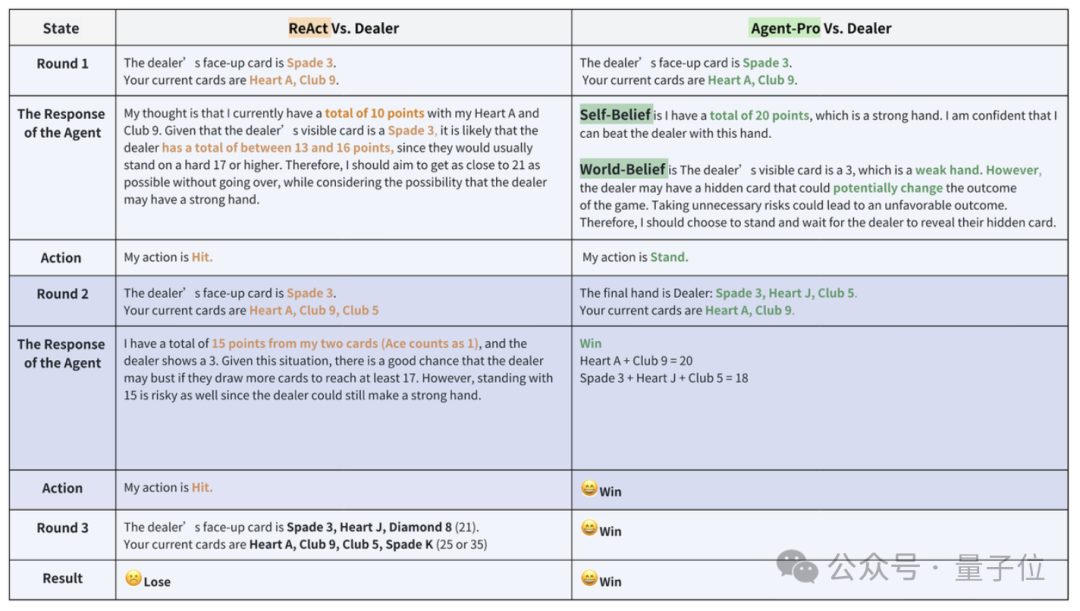
Agent-Pro通过分析得出自我信念(Self-Belief)和对外部天下的信念(World-Belief),正确意志到我方的手牌已接近21点,合理的选拔了停牌。
而ReAct则未能实时停牌,导致最终爆牌,输掉了游戏。
从游戏中粗略看出Agent-Pro更好的诱骗了游戏的轨则,并给出了合理的选拔。
接下来再望望在德州扑克中Agent-Pro的发挥。
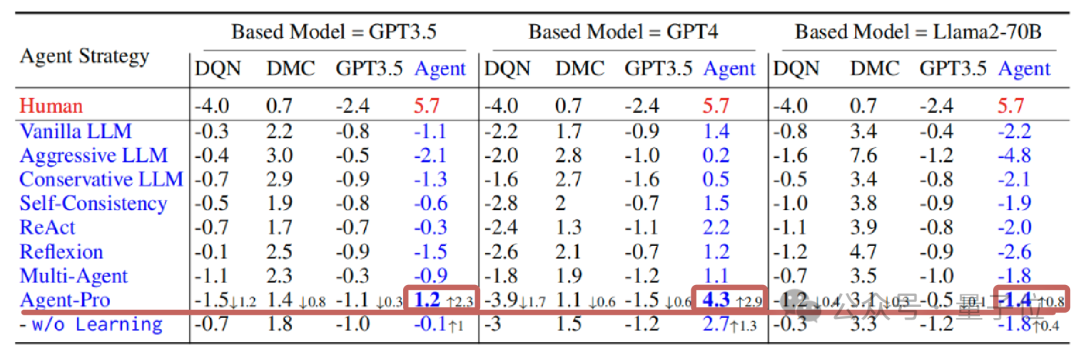
一次牌局中,参赛选手分手是陶冶后的DQN、DMC战略,原生GPT3.5和Agent-Pro(基于GPT-4),他们的手牌和全球牌如下图所示:

△
S、H、C、D分手代表黑桃、红桃、梅花、方块
在现时游戏情状(Current game state)下,Agent-Pro分析得出Self-Belief、World-Belief和最终的Action,并跟着游戏情状的变化,束缚更新Belief,凭据自己和敌手的情况,作念出无邪合理的选拔。

△
换取牌局归拢位置的Baseline(原始大模子)效果为-13
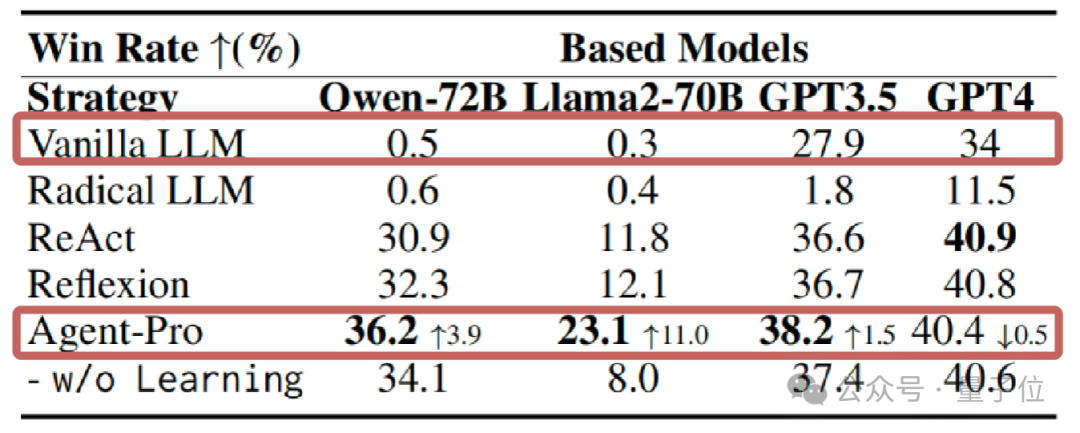
统计数据上看,神秘顾客资讯21点游戏中,在使用GPT、Llama等多种大模子的情况下,Agent-Pro的发挥都显赫跳跃了原始模子和其他参与对比的Agents框架。
在更为复杂的德州扑克游戏中,Agent-Pro不仅跳跃了原始大模子,还打败了DMC等陶冶后的强化学习Agent。
那么,Agent-Pro是如何学习和进化的呢?
三管都下造就Agent发挥
Agent-Pro包括“基于信念的有沟通”“战略层面的反想”和“天下模子和步履战略优化”这三个组件。
基于信念的有沟通(Belief-aware Decision-making)
Agent-Pro凭据环境信息,领先变成Self-Belief和World-Belief,然后基于这些Belief作念出有沟通(Action)。
在后续环境交互中,Agent-Pro动态更新Belief,进而使作念出的Action相宜环境的变化。
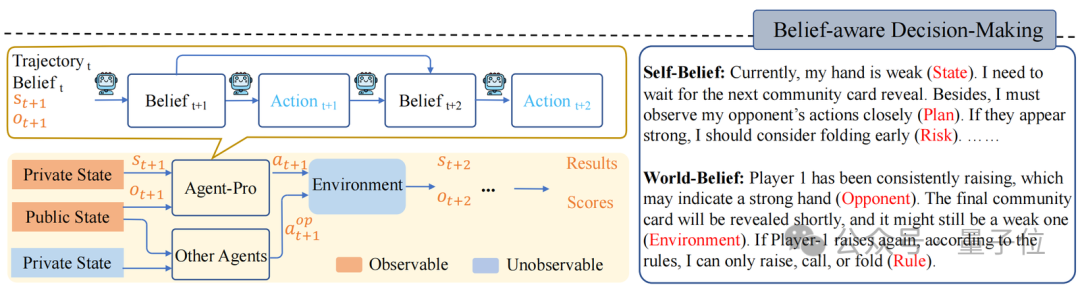
举例,德州扑克游戏中:
环境信息可包括手牌(Private State)、全球牌(Public State)、步履轨迹(Trajectory)等;
Agent-Pro敌手牌(State)、出牌沟通(Plan)及潜在风险(Risk)的预估等信息组成了它的Self-Belief;
而Agent-Pro对敌手(Opponent)、环境(Environment)和轨则(Rule)的诱骗则组成了它的World-Belief;
这些Belief在每一个有沟通周期中都会被更新,从而影响下个周期中Action的产生
战略层面的反想(Policy-Level Reflection)
与东谈主类一样,Agent-Pro 会从历史训导、历史明白和历史效果中进行反想和优化。它自主调养我方的Belief,寻找有用的教导指示,并将其整合到新的战略Policy中。
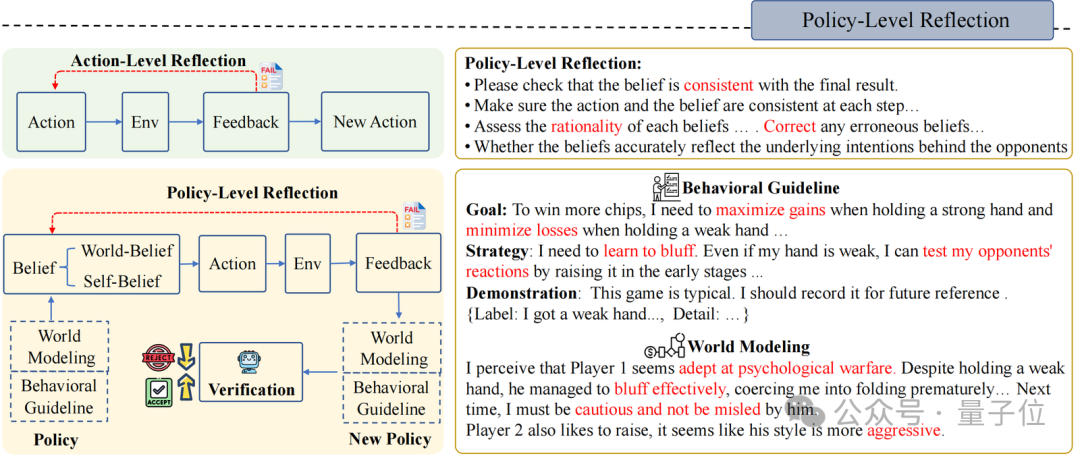
领先,Agent-Pro以翰墨的状貌瞎想了一个对任务天下的建模以及对步履准则的描述, 他们一谈被作为念Policy:
World Modeling:任务天下的建模,举例对游戏环境的诱骗、敌手们的格调分析、环境中其他Agent的战略计算等;
Behavioral Guideline:步履准则的描述,举例对游戏认识的意志、我方战略沟通、将来可能濒临的风险等
其次,为了更新World Modeling和Behavioral Guideline,Agent-Pro瞎想了一个Policy-level Reflection流程。
与Action-level Reflection不同,在Policy-level的反想中,Agent-Pro被指挥去存眷内在和外皮信念是否对都最终效果,更艰巨的是,反想背后的天下模子是否准确,步履准则是否合理,而非针对单个Action。
举例,德州扑克游戏中Policy-level的反想是这么的:
在现时天下模子和步履准则(World Modeling & Behavioral Guideline)的指导下,Agent-Pro不雅察到外部情状,然青年景Self-Belief和World-Belief,临了作念出Action。但淌若Belief不准确,则可能导致不对逻辑的步履和最终效果的失败;
Agent-Pro凭据每一次的游戏来注目Belief的合感性,并反想导致最终失败的原因(Correct,Consistent,Rationality…);
然后,Agent-Pro将反想和对自己及外部天下的分析整理,生成新的步履准则Behavioral Guideline和天下建模World Modeling;
基于重生成的Policy(World Modeling & Behavioral Guideline),Agent-Pro重迭进行换取游戏,来进行战略考证。淌若最终分数有所造就,则将更新后的World Modeling & Behavioral Guideline和保留在教导中。
天下模子和步履准则的优化(World Modeling & Behavioral Guideline Evolution)
在Policy-level Reflection之上,面对动态的环境,Agent-Pro还接受了深度优先搜索(DFS)和战略评估,来不绝优化天下模子和步履准则,从而找到更优的战略。
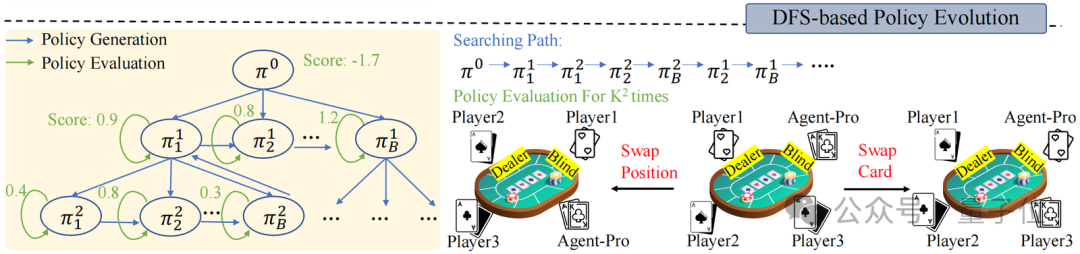
战略评估是指Agent-Pro 在新的采样的轨迹中对新Policy进行更全面的评估,从而磨练新战略的泛化智力。举例,德州扑克游戏中,新采样多条游戏轨迹。
通过交换玩家位置或手牌,来摈斥由于命运带来的飞快身分,从而更全面评估新战略的智力。
而DFS搜索则在新战略不可在新的场景中带来预期的调动(战略评估)时使用,按照DFS搜索战略,从其他候选战略中寻找更优的战略。
— 完 —青岛酒店神秘顾客
